
Redis—数据结构
redis中数据结构
- 简单动态字符串SDS
- 双端链表
- 字典(哈希表)
- 跳表
- 整数集合
- 压缩列表
简单动态字符串
sds的结构如下,对c字符串进行简单封装,类似c++中的string。
struct sdshdr { |
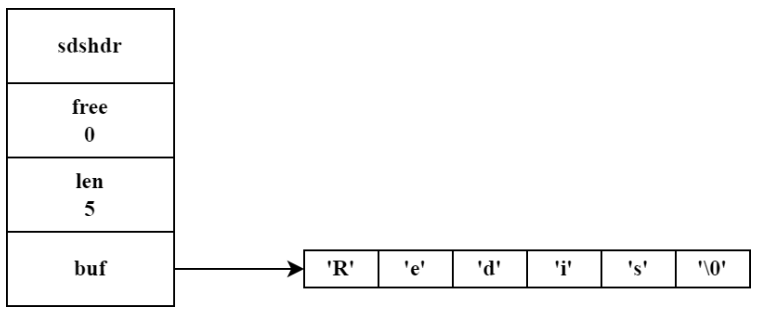
相比c字符串,sds存在下述优势:
- 常数复杂度获取字符串长度
- 避免缓冲区溢出,会自动扩容
- 减少修改字符串带来的内存重新分配次数
- 空间预分配:
sds长度小于1MB(len属性的值),则分配同样大小的未使用空间(free的值);如果sds长度大于1MB,那么分配1MB的未使用空间。 - 惰性空间释放:当
sds需要缩短字符串长度,不会立马释放多余的空间,而是通过修改free的值来记录。
- 空间预分配:
- 二进制安全:
redis不是用这个数组来保存字符,而是保存一系列二进制数据 - 兼容部分
c字符串函数
双端链表
节点结构,包括前驱和后继指针。
typedef struct listNode { |
字典
字典使用哈希表作为底层实现,使用开链法解决哈希冲突,相关数据结构如下。
typedef struct dict { |
字典中有包含两个哈希表,一般情况下只使用ht[0]哈希表,ht[1]哈希表只会对ht[0]哈希表进行重哈希时使用,rehashidx记录重新哈希的进度,如果没有进行重哈希,则它的值为-1。
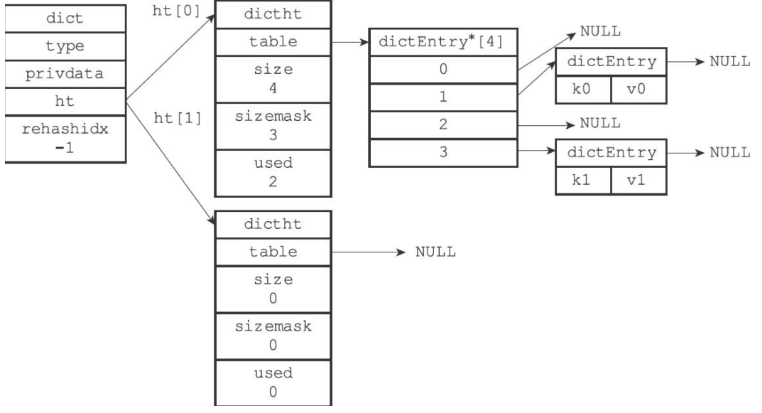
当对哈希表进行扩展或收缩操作时,需要将哈希表包含的所有键值对rehash到新哈希表中,这个rehash的过程不是一次性完成的,而是渐进式完成的,步骤如下。
- 为
ht[1]分配空间,分配大小为第一个大于(当前表大小*2)的2^n - 将字典中的
rehashidx设置成0 - 在
rehash期间,每次对字典执行添加、删除、查找或更新操作,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成后,rehashidx的值加一 - 当
ht[0]的所有键值对都被rehash到ht[1],此时将rehashidx设置成-1 - 渐进式
rehash时,字典会同时使用ht[0]和ht[1]两个哈希表
跳表
跳表(skiplist)是一种有序数据结构,支持平均O(logN)、最坏O(N)复杂度的节点查找。
实现说明:
https://www.jianshu.com/p/9d8296562806
跳表实现类似于二分,第一层数据n个节点,第二层数据n/2个节点左右,第三层数据n/4个节点左右,…,每层节点数据都是顺序排列。当我们从顶层开始,从上往下查找数据,查找速度平均O(logN)。
跳表节点结构如下:
typedef struct zskiplistNode { |
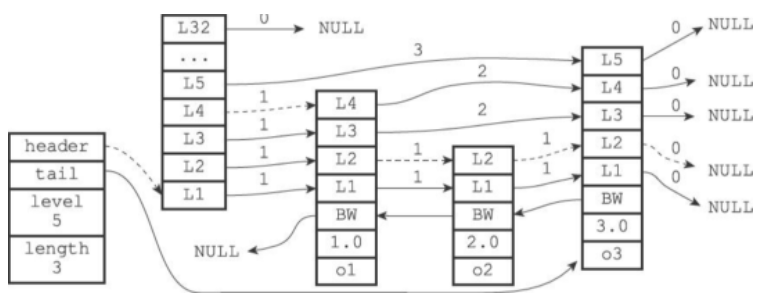
跳表相较红黑树的优点在于,查找一个区间的数据很快,平均效率是O(logN)。
整数集合
整数集合(intset)是redis用来保存整数值的抽象数据结构,可以保存类型为int16_t、int32_t或int64_t的整数值,数据结构如下。
typedef struct intset { |
当需要将一个新元素添加到整数集合中,并且该元素类型比集合中所有元素类型都长,整数集合需要先进行升级,才能将新元素添加到整数集合中。
- 根据新元素类型,扩展整数集合底层数据的空间,为新元素分配空间
- 将底层数组所有元素转换成与新元素相同类型,并将类型转换后的元素放到正确位置上,并且放置元素的过程,需要维持底层数组的有序性质
- 将新元素添加到底层数组
压缩列表
压缩列表式redis为了节约内存而开发的,由一系列特殊编码的连续内存块组成的数据结构。一个压缩列表可以包含多个节点,每个节点可以保存一个字节数组或一个整数值。压缩列表组成部分如下。

| 属性 | 类型 | 长度 | 作用 |
|---|---|---|---|
| zlbytes | uint32_t | 4 | 记录整个压缩列表占用内存的字节数 |
| zltail | uint32_t | 4 | 记录压缩列表表尾节点距离压缩列表的起始地址由多少个字节 |
| zllen | uint16_t | 2 | 记录压缩节点包含的节点数,当节点数据大于65535时,节点数目需要遍历压缩列表才能计算出 |
| entryX | 列表节点 | 不定 | 压缩列表的各个节点 |
| zlend | uint8_t | 1 | 特殊值255 |
压缩节点的构成。
previous_entry_length:记录压缩列表前一个节点的长度encoding:记录节点content属性保存数据的类型及长度content:保存节点值